Lesson 3: Intrinsic Data Quality
Intrinsic data quality references the inherent characteristics of data that make it reliable independent of how it is used in specific applications or contexts. This dimension of data quality focuses on the fundamental attributes of the data, including the extent to which information contained in the data is correct (accuracy), reliable (believability), credible (reputation), and impartial (objectivity).
Ensuring high intrinsic data quality within records is crucial for supporting effective decision-making, legal compliance, and operational efficiency within any administrative data system. High intrinsic data quality translates to high levels of transparency and reliability in the management of sensitive information. Regular data audits, staff training, and robust data management practices are essential for upholding intrinsic data quality in any dataset.
Ensuring high intrinsic data quality means ensuring a high degree of confidence that the data has a solid foundation for however it may be used (e.g., operations decisions, research, population management). Maintaining high intrinsic data quality is important for these main reasons:
Trust: High intrinsic data quality ensures that any users, stakeholders, and analysts can rely on the data to be accurate.
Decision-Making: High intrinsic data quality ensures that any decisions that are made using the data are appropriate and effective.
Operational Efficiency: High intrinsic data quality ensures that any operations decisions that are based on data are accurate and efficient.
Compliance: Maintaining high-quality data is important for meeting any regulatory requirements or standards.
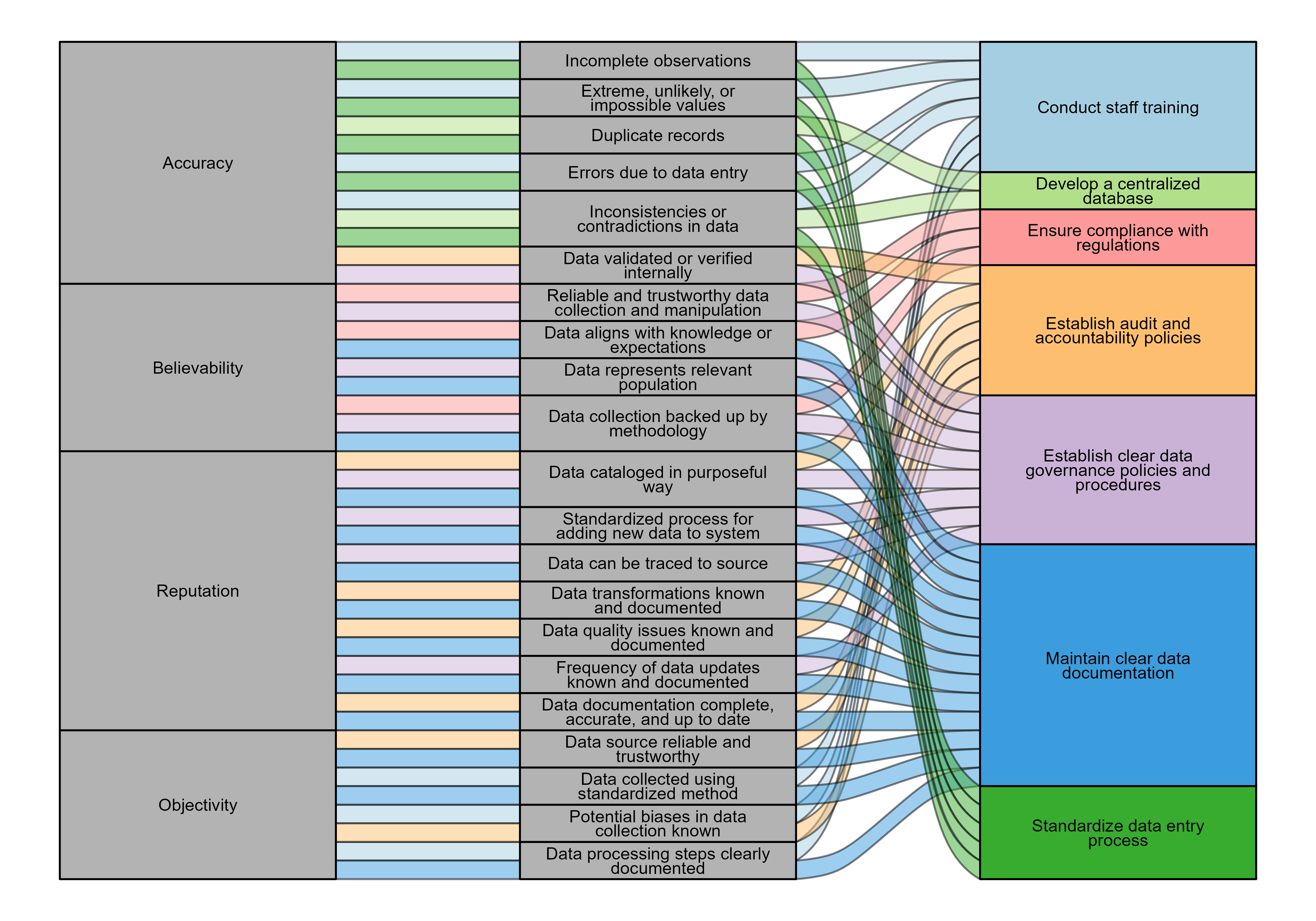
Intrinsic data quality consists of four attributes: (1) accuracy, (2) believability, (3) reputation, and (4) objectivity. Accuracy and objectivity are objective measures of intrinsic data quality that can be clearly quantified and assessed. However, believability and reputation are subjective attributes that reflect the level of trust in the data sources and the processes through which the data are collected, entered, and maintained in databases. To sustain high-quality datasets, analysts must maintain data quality standards, assess their data system to address any problems, and continuously work to improve intrinsic data quality.
| Quality Attribute | Definition | Example |
|---|---|---|
| Accuracy | The extent to which data are correct, reliable, and certified free of error | Information about incarcerated people, such as sex, age, race, ethnicity, criminal history, and prison misconduct is recorded correctly without errors or discrepancies. |
| Believability | The extent to which data are correct, reliable, and certified free of error | Belief that disciplinary records are maintained to document incidents and rule violations |
| Reputation | The extent to which information is highly regarded in terms of its source and content | Validated assessments of an individual’s risk level, rehabilitation needs, or readiness for parole, supported by reliable data sources and professional judgment |
| Objectivity | The extent to which data are unbiased (unprejudiced) and impartial | Data are recorded from official incident reports, behavioral assessments, with facts and evidence-based conclusions. |
The following sections discuss each attribute in more detail and guide you through questions to consider when beginning to understand and assess intrinsic data quality. Additionally, the components of each attribute are tied to a list of best practices that you and your agency can employ to ensure that your data maintains high intrinsic quality. Explanations are provided for each best practice along with how you can maintain each practice. This discussion is theoretical and is to help you understand fundamental concepts of data quality that can help you make more informed decisions when using the data in your system and implement strategies for best practices (when feasible and in your control). Some of these strategies may be easier for you to integrate into your own work (e.g., checking for duplicates, identifying data entry errors), while others may require policy change within your agency (e.g., data verification processes, data integration policies). This lesson is designed to provide you with an understanding of these concepts so you can evaluate your system and propose solutions based on the best practices for maintaining high intrinsic data quality.
Accuracy
Definition: The extent to which data are correct, reliable, and certified free of error.
The accuracy of the data refers to how closely it represents the true or intended values. In corrections data, this means that information about incarcerated people, like personal details, criminal history, and case details, is recorded correctly without errors or discrepancies. Assessing data accuracy involves deciding how to handle data discrepancies, missing data, inconsistent coding, and other data entry errors.
Assessing the accuracy of data requires asking questions that can help identify potential errors or inconsistencies in a data source. Consider the following questions when assessing the accuracy of records and the underlying practices of data inputting and management:
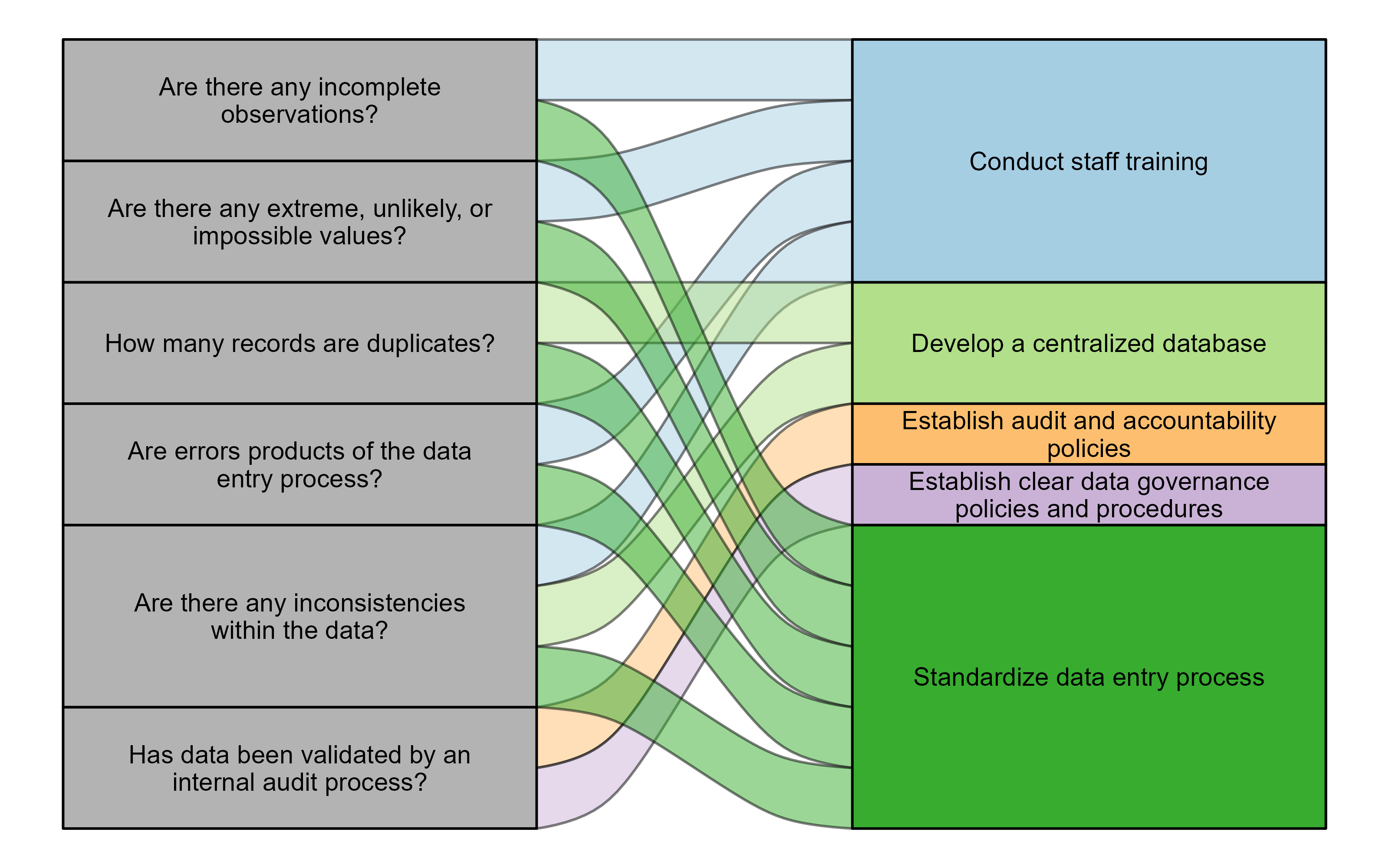
- Are there any incomplete observations?
- Do any entries have extreme values that seem unlikely or impossible?
- How many of the records are duplicates?
- Are the errors (e.g., duplicates, missing values, inconsistent coding of variables, etc.) products of the data entry?
- Are there any inconsistencies (e.g., data in one table contradicts the data in another) within the data?
- Has the data been validated or verified by an internal audit process?
The components of accuracy highlighted in these questions can all be tied to best practices that you (and your agency) can implement to ensure your data is accurate.
Example
Imagine a scenario where you need data on individuals in the custody of the Department of Corrections (DOC) who violated parole and were readmitted to prison. Upon pulling data on parole violation admissions, you discover a data entry error. In some cases, individuals identified as people who violated parole were mistakenly coded. About one-third of individuals had simply been on parole at some point in the past and had not been readmitted to prison due to violations. Yet your data reflects them as people who violated parole.
Further investigation reveals that this error stems from inconsistencies in data entry, and the issue is not uniform across cases. This error highlights significant problems with data accuracy and the potential for incorrect decisions based on flawed data.
Addressing this issue requires implementing standardized data entry processes and establishing robust audit and accountability policies to ensure that such errors are caught early and corrected, ultimately improving the overall quality and accuracy of the data.
Believability
Definition: The extent to which data are accepted or regarded as true, real, and credible.
Believability refers to the degree of trust and confidence that users and stakeholders have in the accuracy and authenticity of the data. In corrections data, believability is important to ensure that the data is considered reliable and credible for use in making informed decisions and conducting analyses within the corrections system.
Assessing the believability of data requires understanding how stakeholders evaluate plausibility and authenticity. Consider the following questions when assessing the believability of data:
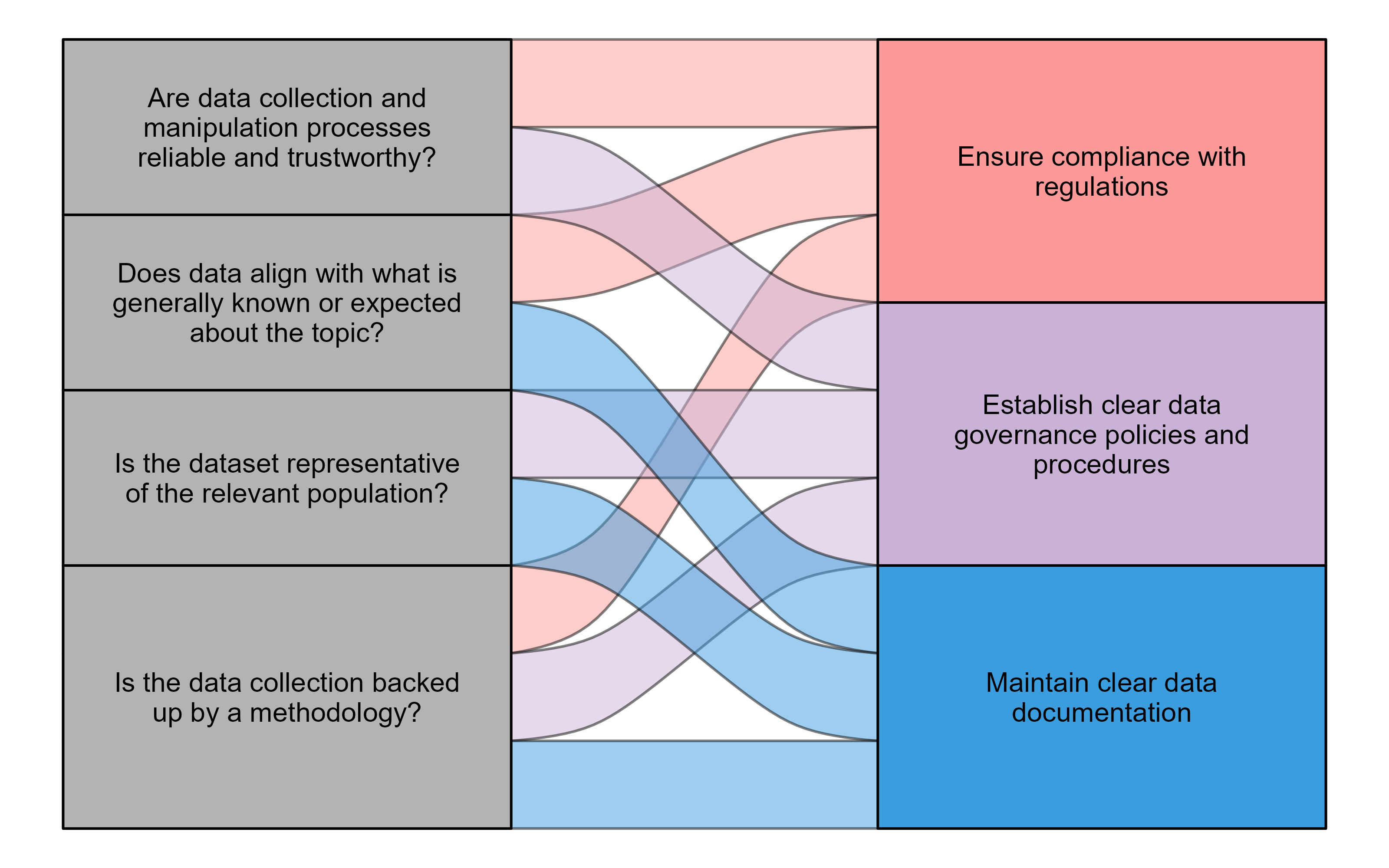
- Are the data collection and manipulation processes reliable and trustworthy?
- Does the data align with what is generally known or expected about the topic or subject matter?
- Is the dataset representative of the relevant population?
- Is the data collection backed up by a methodology?
The components of believability highlighted in these questions can all be tied to best practices that you (and your agency) can implement to ensure your data is believable.
Example
Consider this example of an error that miscalculated prison sentences and led to people being released early1:
A software coding error miscalculated prison sentences and applied good time credits incorrectly, leading up to 3,200 people being released 55 days early, on average. Rather than the calculation only applying good time credits to the regular part of a sentence, it incorrectly applied them to enhancements. This error was identified by a victim’s family who alerted DOC about the premature release of an individual. This led the department to re-calculate the sentence by hand and identify the problem.
This example highlights elements of believability that depend on reliable processes for data collection and manipulation that increase stakeholders’ trust in the data. In this example, an error in data manipulation decreased trust in the data that was used for decisions about release dates.
Reputation
Definition: The extent to which information is highly regarded in terms of its source and content.
Reputation refers to the perceived accuracy, reliability, and integrity of information within the corrections system. It is also associated with the degree of trust and confidence in the accuracy and authenticity of data sources like court records and intake forms. By maintaining high reputation data quality, agencies can make informed decisions about population management, risk assessment, and rehabilitation strategies. Data with high reputation can contribute to the effectiveness and fairness of the corrections system, enhance safety, and support people’s successful reintegration into society.
Assessing the extent to which information is highly trusted in terms of its source and content may be particularly challenging when working with an internal data management system. You are likely to encounter data whose source is unknown. In these cases, instead of focusing on the source, consider how records of data sources are maintained, along with records of any manipulations to original data. Consider the following questions when assessing the reputation of the data:
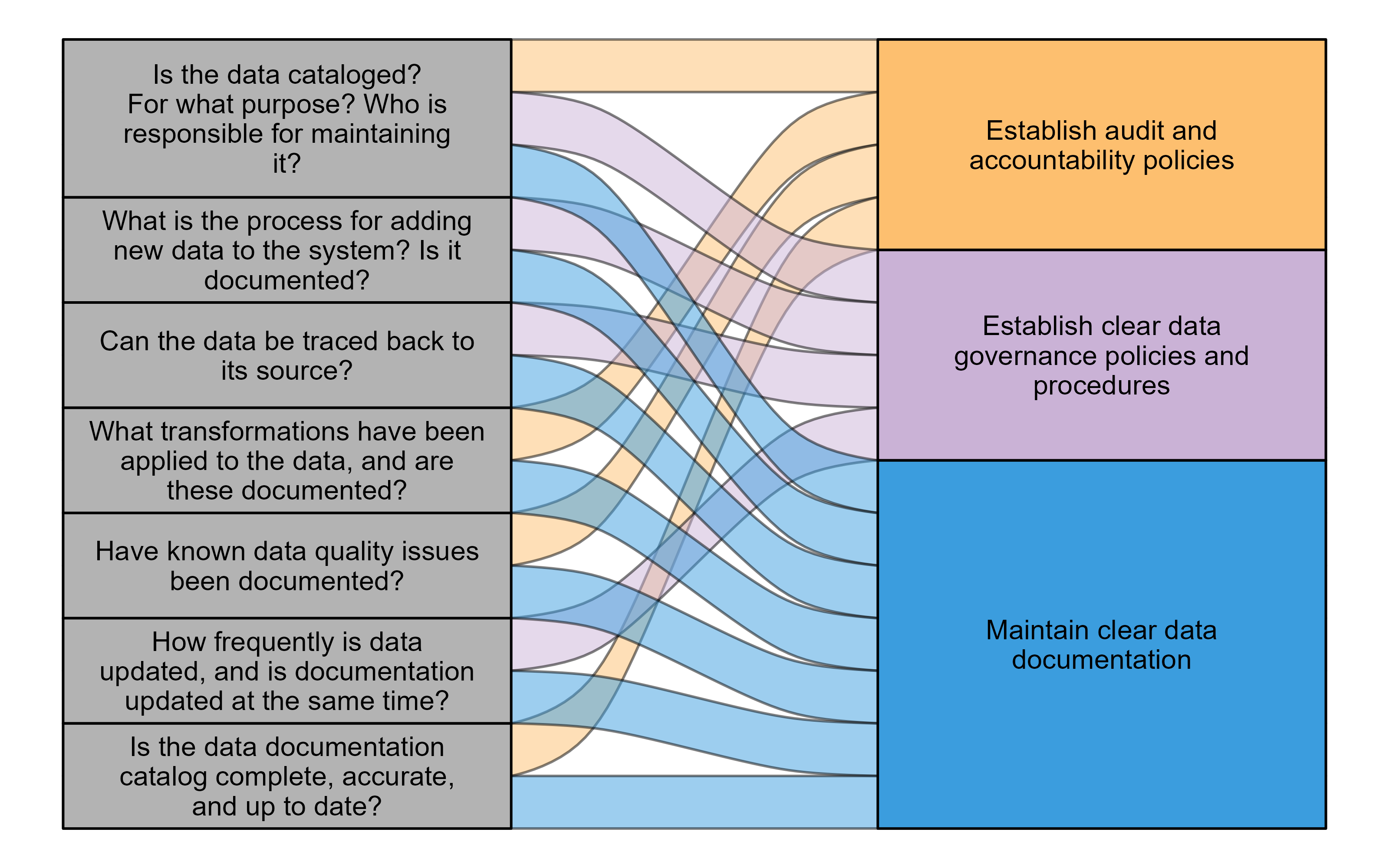
- Is the data cataloged? If so, what is the purpose of the data catalog, and who is responsible for maintaining it?
- What is the process for adding new data to the system? Is there a standard format or template for documenting this process?
- Can the data be traced back to its source?
- What transformations (such as the process of transforming data to extract valuable insights or prepare it for further analysis) have been applied to the data, and are these documented?
- Are there data quality issues? Have these been documented?
- How frequently is the data updated? Does documentation follow a similar cycle?
- Is the data documentation catalog complete, accurate, and up to date?
The components of reputation highlighted in these questions can all be tied to best practices that you (and your agency) can implement to ensure the reputation of your data.
Example
The data that is managed in your system might come from different sources and contain different types of information. Your system should be able to track all this data and connect it. When data is input into your system from a variety of sources, consider creating a codebook that can help collect common variables across multiple data systems. This codebook can outline an interchange policy that describes the data to be shared along with the file and structure requirements. This policy may ensure that the system can track the data source, update frequency, and variables that are shared from other systems. See the example of an interchange policy below.
Consider that risk assessment data is collected in a separate system, but you need this information to be integrated into your management system for incarcerated people to identify their risk scores. Because the data originates from different software, it is crucial to collect additional dependent information to ensure proper matching and integration.
Objectivity
Definition: The extent to which data are unbiased (unprejudiced) and impartial.
Objectivity refers to the absence of bias or prejudice in the data in official records. Objective data is crucial for maintaining transparency, fairness, and accuracy in the decision-making processes related to the management of incarcerated people and operations within corrections data. Consider the questions below when assessing the objectivity of the data:
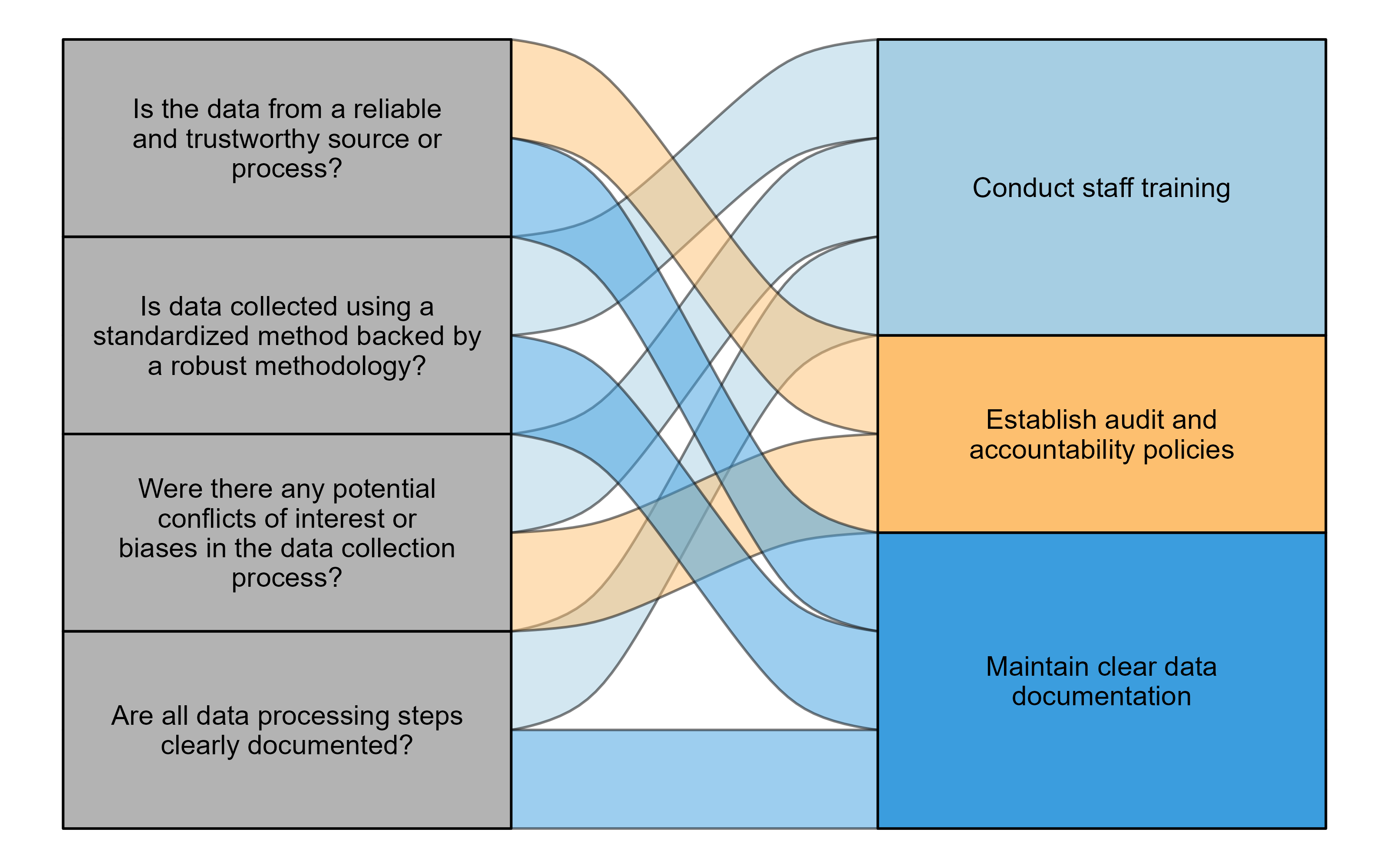
- What is the source of the data? If external, is it from a reliable and trustworthy source? If it is internal, is the data collection process reliable and trustworthy?
- How was the data collected? Was the collection method standardized and backed by a robust methodology to reduce bias?
- Were there any potential conflicts of interest (e.g., data tied to financial incentives) or biases (e.g., data collectors wanting to cast their activities in a better light) in the data collection process?
- Was the data processing transparent with clear documentation of all steps?
The components of objectivity highlighted in these questions can all be tied to best practices that you (and your agency) can implement to ensure your data is objective.
Example
There are multiple ways that agencies can ensure data objectivity. One of the main ways to do this is to ensure that the data collection process is reliable and trustworthy by implementing data verification processes. Consider this example of a verification process:
Best practices
Data that has high intrinsic data quality represents the real world, is believable, has reputation, and is unbiased. If the data can meet these standards, then it would be considered to have “high” intrinsic data quality. However, maintaining high intrinsic data quality is an ongoing process that requires developing and maintaining practices that ensure consistently high-quality data.
High intrinsic data quality can be maintained through a host of best practices that relate to each of these attributes. In the previous sections, the components of each attribute were connected to specific best practices. The table below further explains these best practices, the attributes they are associated with, and the steps you (and your agency) can take to maintain these best practices and high intrinsic data quality.
| Practice | Attribute |
|---|---|
| Establish clear data governance policies and procedures. | Accuracy, Believability, Reputation |
| Ensure compliance with relevant internal and external regulations. | Believability |
| Establish audit and accountability policies. | Accuracy, Objectivity, Reputation |
| Develop a centralized database. | Accuracy |
| Maintain clear data documentation. | Believability, Reputation, Objectivity |
| Standardize data entry process. | Accuracy |
| Train staff. | Accuracy, Objectivity |
Establish clear data governance policies and procedures
Create policies that dictate how to maintain the data management infrastructure. This process should be designed to ensure that data are managed consistently and transparently in a controlled environment. When developing these policies, consider the needs of the agency that owns the data, staff who will enter/maintain the data, anyone who will use the data, and individuals who consume data analysis products. Be clear about who possesses the data and is responsible for the information stored in the database by defining data ownership and usage policies.
Ensure compliance with relevant internal and external regulations
Create policies, procedures, and guidelines that outline regulations and necessary tasks to ensure compliance. Make compliance records available to all internal and external stakeholders.
Establish audit and accountability policies
Create a clear policy for keeping detailed records of data modifications, access logs, and the review process for continuous monitoring. Additionally, develop evaluation processes to continuously make informed decisions about how to improve the process and maintain objectivity. Periodically audit the data to remove duplicates, resolve missing values, and follow up on incomplete records. Put in place mechanisms to track data quality issues as they arise. Disseminate any changes made due to audits to relevant audiences (e.g., data users).
Develop a centralized database
Create a centralized database (i.e., stored and maintained in a single location) to host all data that has limited levels of access that are clearly defined. A centralized database ensures that all data is stored in one place, which is important for data security, operational efficiency, and better decision-making. Maintaining a central database ensures that everyone using the data has access to the most current and accurate information.
Maintain clear data documentation
Establish a clear data catalog to track the flow of data from its origin to its destination, which is known as data lineage. Develop guidelines to ensure that each step in the process (e.g., data sources, input, cleaning, etc.) is noted and detailed with information on who manipulates the data, when it takes place, and how it’s done.2 Include timestamps, data origin, and documentation of any data transformations or modifications. Documentation of data lineage should be made available to data users who may want to evaluate the source and contents of a dataset.
Standardize the data entry process
Develop policies, guidance, and/or documentation (e.g., codebooks or data dictionaries) to train and guide data collectors, analysts, and managers on how to minimize biases at each step of the process. Include metadata, such as descriptions of variables, units of measurement, collection dates, and origin of data.3 Ensure that only one persistent set of records is retained. Do this by eliminating local copies and controlling input, deletion, and access to information.
Train staff
Train staff on how to appropriately implement procedures in accordance with data governance, compliance, and data entry policies.
These seven best practices are designed to help you and your agency maintain data with high intrinsic quality. Some of the suggestions outlined in these practices will be discussed further in future lessons (e.g., developing a data dictionary and dealing with missing values). In the next lessons, we will discuss the other dimensions of data quality and build toward assessing your agency’s data quality standards and developing new strategies for ensuring you maintain high-quality data.
Joseph O’Sullivan and Steve Miletich, “‘Totally Unacceptable’: State Knew Thousands of Inmates Released in Error,” The Seattle Times, December 24, 2015, accessed December 2, 2024, https://www.seattletimes.com/seattle-news/politics/inslee-error-releases-inmates-early-since-2002/.↩︎
Ahmed AbuHalimeh, “Improving Data Quality in Clinical Research Informatics Tools,” Frontiers in Big Data 5, (2022), https://doi.org/10.3389/fdata.2022.871897.↩︎
Ikbal Taleb et al., “Big Data Quality Framework: A Holistic Approach to Continuous Quality Management,” Journal of Big Data 8, no. 1 (2021), https://doi.org/10.1186/s40537-021-00468-0.↩︎